Распознавание рукописного ввода - это способность компьютера получать и интерпретировать рукописный ввод. Распознавание текста может производиться «офлайновым» методом из уже написанного на бумаге текста (см. оптическое распознавание символов) или «онлайновым» методом считыванием движений кончика ручки, к примеру по поверхности специального компьютерного экрана.
Энциклопедичный YouTube
-
1 / 5
Интерфейс онлайнового распознавания обычно состоит из:
- ручки или стилуса, которым пользователь осуществляет ввод
- поверхности, чувствительной к касаниям, которая может быть интегрирована с дисплеем
- программного обеспечения, которое интерпретирует движения стилуса по пишущей поверхности, переводя получившиеся линии в цифровой текст
Распознавание рукописного ввода широко используется в КПК . Первым КПК, который был способен распознавать рукописный ввод, является Apple Newton .
Устройства
Серийные устройства, в которых в качестве альтернативы традиционному вводу с помощью клавиатуры использовался ввод рукописного текста появились в начале 1980-х. Это были, например, терминалы с рукописным вводом, такие как Pencept Penpad и Inforite point-of-sale terminal . С расширением рынка персональных компьютеров появились несколько коммерческих продуктов, призванных заменить клавиатуру и мышь на персональных компьютерах единственной системой, предоставляемые PenCept , CIC and others. Первым, находящимся в открытой продаже, планшетным компьютером был GRiDPad от GRiD Systems, выпущенный в сентябре 1989. Его операционная система была основана на MS-DOS .
В начале 90-х производители аппаратного обеспечения, включая NCR , IBM и EO, выпустили планшетные компьютеры с операционной системой PenPoint, разработанной GO Corp. PenPoint использовала рукописный ввод повсюду и обеспечивала совместимость со сторонним программным обеспечением. Планшетный компьютер IBM был первым использующим ThinkPad и распознавание рукописного текста IBM. Эта система распознавания была позже портирована в Microsoft Windows for Pen Computing и IBM"s Pen для OS/2 . Ни одна из этих технологий не имела коммерческого успеха.
Развитие электроники позволили вычислительной мощности, необходимой для распознавания рукописного ввода, умещаться в меньшие размеры, чем у планшетных компьютеров, и использовать распознавание рукописного текста в качестве средства ввода для PDA . Первым PDA , обеспечивающим письменный ввод, был Apple Newton , который продемонстрировал общественности достоинства такого рода пользовательского интерфейса. Однако устройство не было коммерчески удачным вследствие несовершенства программного обеспечения, которое должно было пытаться изучить манеру письма пользователя. После разрыва с Apple Newton , технология была портирована в Mac OS X 10.2 и более поздние в виде технологии Inkwell (Macintosh).
Современная система распознавания рукописного текста включается в операционные системы Microsoft , используемые на планшетных компьютерах (см. Windows XP Tablet PC Edition и Windows Vista). Она основана на TDNN-классификаторе, названном «Inferno», созданном в Microsoft . Позже версия CalliGrapher, распознающего рукописных ввод программного обеспечения, используемого в Newton OS 2.0, была включена в качестве вторичного распознавателя. Новое поколение CalliGrapher в настоящее время разрабатывается для Windows Mobile корпорацией PhatWare.
Технология распознавания рукописного ввода «третьего поколения» riteScript, разработанная корпорацией EverNote в 2000-2004, включается в ritePen and EverNote. ritePen также включает технологию, позволяющую комбинировать riteScript со встроенным распознаванием рукописного текста Windows Vista , чтобы улучшить точность распознавания каждого движка распознавания рукописного текста.
Хотя распознавание рукописного текста - средство ввода, к которому уже привыкла общественность, оно ещё не достигло широкого распространения в настольных компьютерах и ноутбуках. Все ещё считается [ ] , что ввод с помощью клавиатуры быстрее и надежнее. Сейчас существует множество PDA, поддерживающих иногда и естественный рукописный почерк, но точность все ещё не является очень высокой, из-за чего некоторые люди находят даже простую экранную клавиатуру более эффективной.
Офлайновое распознавание
Этот вид распознавания считается более сложным по сравнению с онлайновым. Для офлайного распознавания требуется обучение системы распознавания человеком или готовая обучающая выборка. Подобный механизм реализован в ABBYY FineReader . Качество распознавания можно повысить, используя структурированные документы (формы). Кроме того, можно улучшить качество, уменьшив диапазон возможных вводимых символов. Применяется в сферах деятельности, где необходимо обрабатывать большое количество рукописных документов, к примеру, в страховых компаниях.
Достаточно значимый процент деловых и офисных документов содержит рукописный текст. Согласно исследованиям , эти данные играют ключевую роль и в обязательном порядке попадают в учетные системы путем ручного ввода. Предприятия не пытаются автоматизировать эту работу, в результате, ввод данных отнимает много ресурсов и времени. Почему? Рукописный текст, также как и печатный, можно извлекать из документов, получая при этом максимальную точность. Предлагаемое решение Form Xtra Capture , как нельзя лучше, подходит для этих задач. Теперь распознавание рукописного текста, цифр, образов полностью автоматизировано.
Привычные многим программы для распознавания текста отличаются от решений по извлечению данных. И на то есть свои причины. Учетным программам нужны данные, а не редактируемые формы с различными графическими элементами (таблицы, рамки, линии, засечки и логотипы). Для автоматизации ввода требуется подготовительный этап — настройка, где пользователь указывает какую информацию извлекать, как ее обрабатывать, распознавать и экспортировать. Для более детального ознакомления с основными этапами работы (в т.ч. и настройки) системы смотрите схему работы . Мы же сосредоточимся на распознавании рукописного текста в документах, выделяя важные особенности:
- Использование контекстной информации
- Использование регулярных выражений
Регулярные выражения — крайне полезный инструмент, который можно использовать для распознавания сложных последовательностей символов.

- Использование псевдонимов
Ошибки в проектировании документа могут приводить к неопределенности при ее заполнении. В результате вместо одного варианта написания появляется множество альтернативных вариантов, которые тоже являются правильными. Для примера: Харкiв , мХаркiв (точка находится в ячейке с буквой "м"), м.Харкiв (точка находится в отдельной ячейке). Более того, специфика различных регионов Украины позволяет смело предположить, что люди заполняют документы на родном языке, игнорируя требования и основной язык документа. Пример: Харьков , гХарьков , г.Харьков . Использование псевдонимов (alias) позволяет преобразовать все ответы распознавателя к единственно правильному ответу.

- Использование скриптов (бизнес-правил)
Скрипты применяют в качестве логического инструмента при распознавании. Они используют теории имплекации (if, else) или сценариев (use, case) для определения следующего корректного ответа или подтверждения достоверности одного или нескольких полей. Распространенной областью применения является автоматическое заполнение полей с поиском в базе данных (например, если код 00123, то имя, адрес и телефон автоматически должны быть х, у, z).

- Алгоритмы голосования
Достаточно часто к извлекаемому рукописному полю предъявляют повышенные требования к точности распознавания. В подобных случаях имеется возможность распознавать одно и тоже поле разными способами или движками (ABBYY FineReader Engee, CuneiForm и прочие), а после, сравнивать ответы для нахождения истины.

Разработчик:
Во все времена людям была присуща лень, а с появлением техники тяга излишне расслабиться усилилась ешё больше. Если раньше люди с удовольствием использовали сенсорную клавиатуру смартфона, наслаждаясь простотой и удобством такого способа ввода текста, то теперь почти никто не хочет утруждать себя даже этим.
Простота и удобство - вот главный девиз устройств начала двадцать первого века. Что может быть лучше, чем взять стилус и написать своей рукой текст, который будет корректно распознан смартфоном? Я думаю, ничего. Именно поэтому сегодня я предлагаю поговорить об одной из таких совершенных программ для распознавания рукописного текста - PenReader .
Penreader - приложение не бесплатное, но, как мне кажется, его стоит купить из - за его некоторых неоспоримых преимуществ:
- Поддержка русского языка
- Поддержка всех версия Android
- Возможность использовать PenRader в любом приложении
- Возможность создания макросов
Эти преимущества просто неоспоримы, так как я не смог отыскать ни одного приложения, которое имело бы все эти возможности. Самое главное - PenReader поддерживает русский язык, поэтому это приложение очень широко распространено в России.
Теперь я расскажу подробнее о том, как работать с PenReader.
Работа с приложением
После установки PenReader из Google Play , нам нужно выбрать язык распознавания, зайдя в меню приложения:
Хочу обратить ваше внимание, что для установки всех языков, кроме Английского, приложению требуется скачать специальную библиотеку.dll из Интернета, а ваш оператор может взять с вам за это деньги. Так что, будьте внимательны.
После установки нужного языка первое, что нужно сделать - опробовать распознавание текста.
Чтобы начать писать текст, нужно прикоснуться к полю ввода текста. После этого, вы перейдёте непосредственно на рабочий экран приложения PenReader , на котором вы увидите само поле рисования и некоторые кнопки:
- «Конфигурация» - нажимая на эту кнопку, вы можете переключаться между языками ввода. Учтите, что выбирать можно только из тех языков, которые отмечены как "Активные" (см. выше)
- «Назад» - нажав на эту кнопку единожды, ваш указатель будет перемещён на один символ назад. Чтобы перейти в начало строки, нужно удерживать эту кнопку
- «Пробел» - вставляет пробел на том месте, где находится курсор.
- «Стереть» - нажав на эту кнопку один раз, вы удалите символ перед курсором. Чтобы удалить всю строку, нужно удерживать кнопку
- «Дополнительно» -открывает и скрывает дополнительные кнопки:
-«Hide» - нажав на эту кнопку, Вы выйдите из рабочего экрана PenReader.
-«Alt» - Переключает режимы ввода. Всего доступна два режима: ввод букв и ввод спецсимволов
-«Верхний регистр» - Если нажать на эту кнопку, то вы введёте следующую букву в верхнем регистре. При повторном нажатии все буквы, введённые вами станут заглавными (функция, аналогичная функции клавиши Caps Lock).
Penreader поддерживает разные режимы распознавания рукописного текста. Всего их 4:
- Слитное распознавание позволяет пользователю писать слова и даже целые предложения привычным для него образом - не отрывая руки от "листа"
- Побуквенное распознавание позволяет распознавать только ожин символ за определённый промежуток времени. Пытаться вводить несколько букв не имеет смысла - PenReader попытается распознать их как один символ
- Интеллектуальное распознавание
позволяет корректировать результаты распознавания
прямо в процессе письма. Например, писать букву "А" можно так:
- Сначала ввести символ "/"
- Затем ввести символ "\"
- А после этого поставить между ними чёрточку "-"
В этом случае программа будет работать так: распознает ввод символа «слэш», затем исправит его на букву Л, а затем - на А.
- Раздельное распознавание даёт программе сигнал, что каждый написанный вами штрих будет распознан как единый символ. Этот способ немного схож с Побуквенным распознаванием
По умолчанию в приложении установлен режим Интеллектуального распознавания, поэтому, если он вам не подходит, то обязательно смените его перед началом работы.
Ниже вы видите пример побуквенного распознавания:
Настройки приложения
Некоторые пункта настроек мы уже рассмотрели выше, поэтому сейчас я расскажу только тех вещах, о которых мы ещё не говорили.
В настройках приложения PenReader есть раздел "Настройка распознавания". В него входят следующие подпункты:
Также мы можем увидеть раздел "Оформление":
- Толщина линии - задаёт толщину линии, выводим на рабочем экране PenReader. Она может колебаться от 1 до 30 пикселей
- Цвет линии - изменяет цвет линии на экране PenReader
- Расположение экранной клавиатуры - изменяет расположение кнопок на рабочем экране при ландшафтной ориентации планшета
- Прозрачность экранной клавиатуры - настраивает уровень прозрачности кнопок на экране ввода
Мы видим очень гибкую систему настроек. С её помощью мы можем подстроить приложение, что называется "под себя", до мельчайших деталей.
В связи с дельной критикой хабрахабровцев, я кардинально переделал пост. Надеюсь, такой вариант будет оценен более положительно.
Я почти два года работаю в компании, которая занимается оцифровкой архивных и библиотечных фондов. Сканирование информации у нас поставлено на поток и в сутки мы получаем десятки тысяч графических образов, которые необходимо распознать и выгрузить заказчику. Моя задача состоит в создании конвейерной технологии для распознавания информации с графических образов.
Тестирование автоматического распознавания
Печатный текст
ABBYY FineReader является безоговорочным лидером в данном сегменте. Программы распознавания разрабатываются с уклоном на стандартную документацию компаний, которые является основными потребителями софта. Они не рассчитаны на нестандартные форматы, поэтому программы не могут дать уровень достоверности выше 80%.При обработке библиотечных карточек десяти-двадцатилетней давности, ABBYY FineReader не может дать результат выше 60% достоверности. Смотрите скриншот ниже.

Рукописный текст
У ABBYY FineReader есть версии программы, где, после обучения, она должна распознавать текст. Суть проста – продукт представляет собой пустую нейронную сеть. Пользователю необходимо ее наполнить вручную. Если пользователь пытается распознать несколько почерков, программа не сможет выдать результат. Потратив неделю времени на обучение такого программного решения, в итоге, мы не получили положительный результат.Применение автоматизированных программ для распознавания рукописного текста на сегодняшний день почти невозможно. Ввод оператором информации с графического образа является единственным способом получения оцифрованной информации. Смотрите скриншот ниже.

Создание технологии ручного распознавания
Далее пойдет речь о технологии, которую необходимо было создать. Был алгоритм, на реализацию которого ушло полгода. Ниже приведен порядок действий для получения распознанного текста:- Сканирование – потоковый сканер выполняет сам.
- Разделение массива графических образов по признаку на подкатегории - это и все дальнейшие этапы выполняет человек. Этот этап позволяет повысить КПД ввода.
- Проверка работы сделанной на предыдущем этапе.
- Ввод данных. Вся информация логически разделяется на поля и заполняется частями. Каждый массив данных имеет свою специфику и свои правила ввода:
- если информация конфиденциальная - изображение автоматически режется на части, и каждый оператор получает для ввода только часть информации;
- при большом количестве полей - поля одной карточки делятся между несколькими операторами.
- Проверка данных ввода. Наличие ошибок влияет на оплату труда людей, которые вводят данные.
- Проводится ряд общих автоматизированных проверок по базе.
- Отгрузка законченных частей массива заказчику.
С ростом нагрузки - на сервере стали возникать новые проблемы по оптимальности алгоритмов и скорости их обработки. Пока они решаются локально, но, вполне возможно, скоро придется проводить оптимизацию всей системы.
Весь проект был реализован при поддержке Министерства культуры и туризма Украины, подробнее можно почитать по ссылке .
Кратко о системе
Язык программирования: PHP.
База данных: MySQL.
CMS, Framework: отсутствуют, разработка велась с нуля.Напоследок
Для тех, кому интересно увидеть различные варианты результатов работы ABBYY FineReader, я опубликовал дополнительные скриншоты по ссылке .Если этот пост будет принят положительно, я опубликую продолжение и расскажу о том, как построена технология автоматизации библиотек в странах СНГ. Особое внимание я уделю модулю с интересными особенностями, который отвечает за отображение информации в интернете.
Если вам необходимо перевести ранее напечатанный текст в электронную форму, то сегодня вам не потребуется набирать его на клавиатуре. Современные технологии существенно упрощают этот процесс. Достаточно отсканировать его или сфотографировать, и обработать специальной программой - распознавателем текста.
Давно прошло то время, когда для получения электронной копии печатного текста, приходилось набирать его на клавиатуре, символ за символом, буква за буквой. Сегодня печатный текст достаточно положить на сканер, нажать одну кнопку, и уже через несколько секунд у вас будет его электронная копия, как будто кто-то уже набрал его для вас. Как же это стало возможным? Как работает распознавание текста?
Системы распознавания текста или OCR-системы (Optical Character Recognition) предназначены для автоматического ввода документов в компьютер. Это может быть страница книги, журнала, словаря, какой-то документ - все, что угодно, что было уже напечатано, и должно быть преобразовано обратно в электронную форму.
OCR-системы распознают текст и различные его элементы (картинки, таблицы) с электронного изображения. Изображение получается обычно путем сканирования документа и реже - его фотографированием. Поступившее изображение обрабатывается алгоритмом OCR-программы, выделяются области текста, изображений, таблиц, отделяется мусор от нужных данных.
На следующем этапе каждый символ сравнивается со специальным словарем символов, и если находится соответствие, то этот символ считается распознанным. В итоге вы получаете набор распознанных символов, то есть искомый текст.
Современные OCR-системы представляют собой достаточно сложные программные решения. Ведь текст может быть замусорен, искажен, загрязнен, и программа должна это учитывать и уметь правильно обрабатывать такие ситуации. Кроме того, современные OCR-системы позволяют также получить копию печатного документа в электронном виде с сохранением форматирования, стилей, размеров текста и видов шрифтов и т.д.
ABBYY FineReader 9.0 Home Edition
Система распознавания текста ABBYY FineReader - это многофункциональная программа для перевода бумажных документов, pdf-файлов, фотографий в редактируемые форматы. Эта версия известной программы для распознавания текста специально предназначена для домашнего пользователя, простая и удобная в использовании. В ней отсутствуют лишние функции и сложные настройки, а интерфейс рассчитан даже на неподготовленного пользователя. Если вам нужно время от времени быстро получать электронные копии страниц каких-то учебников, книг, документов - эта версия OCR-программы для вас.
ABBYY FineReader 9.0 Professional Edition
Эта версия программы ABBYY FineReader для распознавания текста подойдет для использования в офисе или в учебном заведении, а также для продвинутых пользователей, кто хотел бы иметь возможность задавать множество настроек и активно участвовать в процессе распознавания текста. Возможности программы позволяют вам отсканировать и распознать документы, проверить результат распознавания на ошибки, исправить их автоматически или вручную, и сохранить документ в одном из множества форматов (txt, doc, pdf и др.). Программа умеет работать с сетью: пересылать документы по электронной почте, размещать их в хранилища информации, использовать сетевое оборудование (сканеры и МФУ).
ABBYY FineReader 9.0 Corporate Edition
Специальная версия программы ABBYY FineReader для распознавания текста, предназначенная для использования в крупных фирмах, для организации электронных архивов документов. Система позволяет организовать полноценную работу по распознаванию текста внутри большой компании, размещение результатов в электронных хранилищах, использование сетевого оборудования.
ABBYY Business Card Reader
Эта программа предназначена для мобильных устройств (смартфонов), позволяющая быстро вводить в записную книжку контактную информацию с визитных карточек. ABBYY Business Card Reader будет удобна для деловых людей, бизнесменов, менеджеров, всех, кто часто сталкивается с визитными карточками. Программа поддерживает 16 языков.
Readiris 12 Pro
Readiris Pro - многофункциональная OCR-система, которая подойдет как домашним пользователям, так и профессионалам. При помощи этой программы вы можете быстро преобразовать любой документ, PDF-файл, изображение в редактируемый текст, и затем сохранить его в один из множества популярных форматов. Программа имеет простой и приятный интерфейс со множеством дополнительных возможностей и полезных инструментов: сжатие файлов, работа с изображениями, функции экспорта, и др.
Readiris 12 Corporate

 - OCR-система, которая специально предназначена для использования в крупных компаниях, офисах, а также для создания электронных архивов. Программа обладает теми же возможностями, что и версия Readiris Pro, плюс еще дополнительные инструменты и настройки для работы с сетью и сетевым оборудованием. Поддерка азиатских языков, иврита, фарси устанавливается отдельно.
- OCR-система, которая специально предназначена для использования в крупных компаниях, офисах, а также для создания электронных архивов. Программа обладает теми же возможностями, что и версия Readiris Pro, плюс еще дополнительные инструменты и настройки для работы с сетью и сетевым оборудованием. Поддерка азиатских языков, иврита, фарси устанавливается отдельно. 
OCR-система, которая распространяется совершенно бесплатно. Программа обладает множеством возможностей, практически не уступая коммерческим версиям. В данный момент SimpleOCR умеет распознавать тексты на английском и французском языках.
Ввод китайских иероглифов при помощи мыши или планшета
 - полезная программа для тех, кто работает с китайским языком. NJStar Chinese Pen позволяет вводить китайские иероглифы простым рисования их при помощи мыши или планшета. Это намного быстрее и удобнее, чем набирать иероглифы на клавиатуре по определенным правилам.
- полезная программа для тех, кто работает с китайским языком. NJStar Chinese Pen позволяет вводить китайские иероглифы простым рисования их при помощи мыши или планшета. Это намного быстрее и удобнее, чем набирать иероглифы на клавиатуре по определенным правилам.Программа поддерживает как китайский традиционный, так и китайский упрощенный. Набранный текст можно озвучивать (произносить) при помощи встроенного speech-движка. Все параметры программы полностью настраиваются.
NJStar Chinese Pen поддерживает все версии операционной системы Windows. Для работы программы требуется примерно 50 Мб свободного места на жестком диске.

ArioForm
MyScript Studio

MyScript Studio - решение для оцифровки документов и заметок, созданных «от руки». Программа будет полезна всем деловым людям, менеджерам, журналистам, и всем остальным, кто часто делает рукописные заметки. При помощи этой программы вы сможете быстро перевести в электронную форму все ваши заметки, записи и рукописные документы, распознать текст и организовать электронный архив.
Распознавание рукописного текста MyScript Stylus

MyScript Stylus - программа для распознавания рукописного текста. Текст можно вводить при помощи мыши или планшета. Программа распознает текст по технологии, применяющейся в кпк, и может использоваться там, где нет возможности использовать стандартную клавиатуру или ее использование затруднено (например, если компьютер используется как терминал для ввода/вывода информации, как платежный терминал). Вы можете закрепить MyScript Stylus за определенной программой, и весь распознаваемый текст будет передаваться ей, как-будто текст вводится стандартным способом. MyScript Stylus поддерживает 26 языков.
PenOffice
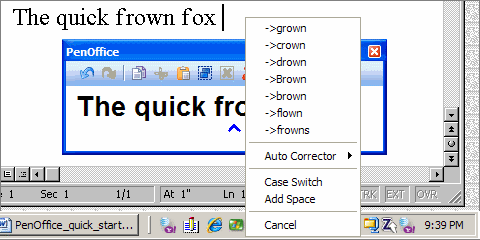
PenOffice - программа для распознавания рукописного текста. PenOffice был специально создан для интеграции с программами пакетов Microsoft Office и OpenOffice, но позволяет вводить распознанный текст также и в другие программы. Программа позволяет распознавать 9 языков: английский, испанский, итальянский, голландский, французский, немецкий, норвежский, португальский и шведский.
CalliGrapher

CalliGrapher - программа ввода рукописного текста для кпк и смартфонов под управлением Windows Mobile. Программа распознает рукописный текст и сразу же вводит его в текстовый редактор в выбранном стиле. Вы можете писать текст в любом месте экрана. CalliGrapher имеет встроенную виртуальную клавиатуру, систему проверки правописания и многоязыковую поддержку.